Apache Spark Er et dataanalyseverktøy som kan brukes til å behandle data FRA HDFS, S3 eller andre datakilder i minnet. I dette innlegget vil vi installere Apache Spark på En Ubuntu 17.10-maskin.
Ubuntu Versjon
For denne veiledningen vil vi bruke Ubuntu versjon 17.10 (GNU/Linux 4.13.0-38-generisk x86_64).
Apache Spark er en del Av Hadoop-økosystemet for Big Data. Prøv Å Installere Apache Hadoop og lage et prøveprogram med det.
Oppdatere eksisterende pakker
for å starte installasjonen For Spark, er det nødvendig at vi oppdaterer maskinen vår med de nyeste programvarepakkene som er tilgjengelige. Vi kan gjøre dette med:
Som Spark er basert På Java, må vi installere Den på vår maskin. Vi kan bruke Hvilken Som Helst Java-versjon over Java 6. Her vil Vi bruke Java 8:
Nedlasting Av Spark-filer
alle nødvendige pakker finnes nå på maskinen vår. Vi er klare til å laste ned De nødvendige Spark TAR-filene, slik at vi kan begynne å sette dem opp og kjøre et prøveprogram med Spark også.
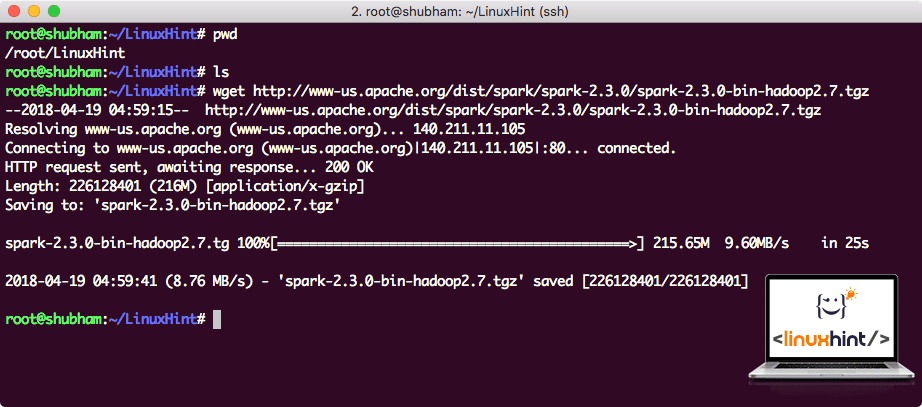
i denne veiledningen vil vi installere Spark v2.3.0 tilgjengelig her:

Spark nedlastingsside
Last ned de tilsvarende filene med denne kommandoen:
Avhengig av nettverkshastigheten kan dette ta opptil noen få minutter da filen er stor i størrelse:
Laster Ned Apache Spark
Nå som VI har TAR-filen lastet ned, kan vi trekke ut i gjeldende katalog:
dette vil ta noen sekunder å fullføre på grunn av stor filstørrelse på arkivet:

Ikke Arkiverte filer I Spark
når Det gjelder å oppgradere Apache Spark i fremtiden, kan det skape problemer på Grunn Av Sti oppdateringer. Disse problemene kan unngås ved å opprette en softlink Til Gnist. Kjør denne kommandoen for å lage en softlink:
Legge Gnist Til Banen
for å utføre Gnist skript, vil vi legge den til banen nå. For å gjøre dette, åpne bashrc-filen:
Legg disse linjene til slutten av den .bashrc-fil slik at banen kan inneholde Spark kjørbar filbane:
eksporter STI= $ SPARK_HOME / bin:$STI
nå ser filen ut som:

Legge Spark TIL BANE
kjør følgende kommando for bashrc-fil for å aktivere disse endringene:
Lansere Spark Shell
nå når vi er rett utenfor spark-katalogen, kjør følgende kommando for å åpne apark shell:
Vi vil se At Spark shell er openend nå:

Lansering Spark shell
Vi kan se i konsollen At Spark også har åpnet En Webkonsoll på port 404. La oss gi det et besøk:

Apache Spark Web Console
selv om vi skal operere på konsollen selv, er webmiljø et viktig sted å se på når du utfører tunge Spark-Jobber, slik at du vet hva som skjer i Hver Spark-Jobb du utfører.
Sjekk Spark shell-versjonen med en enkel kommando:
Vi kommer tilbake noe som:
Å Lage et Eksempel På Spark-Program Med Scala
Nå skal Vi lage et Eksempel På Word Counter-program Med Apache Spark. For å gjøre dette, må du først laste inn en tekstfil I Spark Context På Spark shell:
data: org. apache.gnist.rdd.RDD = / root / LinuxHint / spark / README. md MapPartitionsRDD på textFile på :24
scala>
nå må teksten som er tilstede i filen, brytes inn i tokens som Spark kan klare:
polletter: org. apache.gnist.rdd.RDD = MapPartitionsRDD på flatMap på: 25
scala>
nå initialiser tellingen for hvert ord til 1:
tokens_1: org.apache.gnist.rdd.RDD = MapPartitionsRDD på kart på: 25
scala>
til slutt beregner du frekvensen av hvert ord i filen:
Tid til å se på utgangen for programmet. Samle tokens og deres respektive teller:
res1: Array = Array ((pakke,1), (For, 3), (Programmer, 1), (behandling., 1), (Fordi, 1), (Den, 1), (side] (http://spark.apache.org/documentation.html).,1), (klynge.,1), (its,1), ([run,1), (enn,1), (Apier,1), (har,1), (prøve,1), (beregning,1), (gjennom,1), (flere,1), (dette,2), (graf,1), (Hive,2), (lagring,1), ([«Spesifisere,1), (Til,2), («garn»,1), (En Gang,1), ([«Nyttig,1), (foretrekker,1), (sparkpi,2), (motor,1), (versjon,1), (fil,1), (dokumentasjon,,1), (behandling,,1), (den,24), (er,1), (systemer.,1), (params, 1), (ikke,1), (forskjellig, 1), (se,2), (Interaktiv,2), (R,, 1), (gitt., 1), (hvis, 4), (bygge, 4), (når, 1), (være, 2), (Tester, 1), (Apache, 1), (tråd, 1), (programmer,, 1), (inkludert, 4), (./ bin / run-eksempel, 2), (Spark., 1), (pakke.,1), (1000).antall (), 1), (Versjoner, 1), (HDFS, 1), (D…
scala>
Utmerket! Vi var i stand til å kjøre et Enkelt Word Counter eksempel ved Hjelp Av scala programmeringsspråk med en tekstfil som allerede finnes i systemet.
Konklusjon
i denne leksjonen så vi på hvordan Vi kan installere Og begynne Å bruke Apache Spark På Ubuntu 17.10-maskinen og kjøre et prøveprogram på det også.
Les Flere Ubuntu-baserte innlegg her.