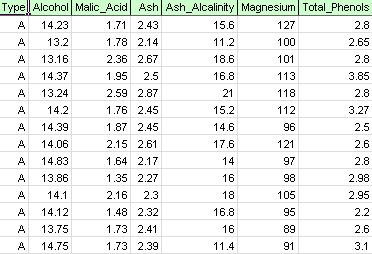
På xlminer-båndet, fra Bruk Av Modell-fanen, velg Hjelpeeksempler, Deretter Prognoser / Data Mining-Eksempler, og åpne eksempelfilen Wine.xlsx. Som vist i figuren nedenfor representerer hver rad i dette eksempeldatasettet et utvalg vin tatt fra en av tre vinprodusenter (A, B eller C). I dette eksemplet ignoreres typevariabelen som representerer vingården, og klyngen utføres bare på grunnlag av egenskapene til vinprøvene (de resterende variablene).
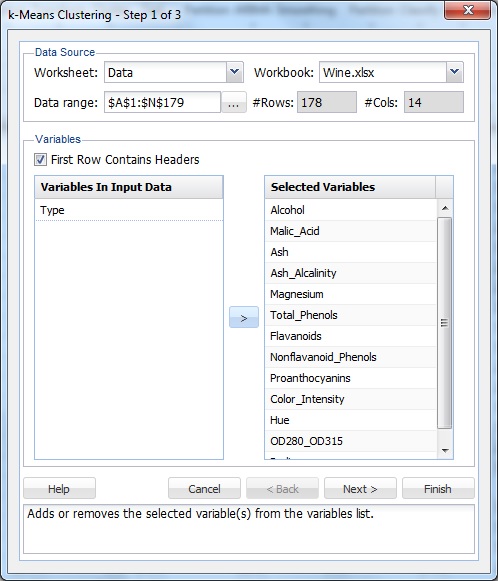
Velg en celle i datasettet, og velg Deretter xlminer – Cluster – K-Means Clustering På Xlminer-båndet I Kategorien Dataanalyse For å åpne dialogboksen K-Means Clustering Trinn 1 av 3.
velg alle variabler unntatt Type fra Variabellisten, og klikk deretter på > – knappen for å flytte de valgte variablene til Listen Valgte Variabler.
klikk Neste for å gå videre Til trinn 2 av 3 dialog.
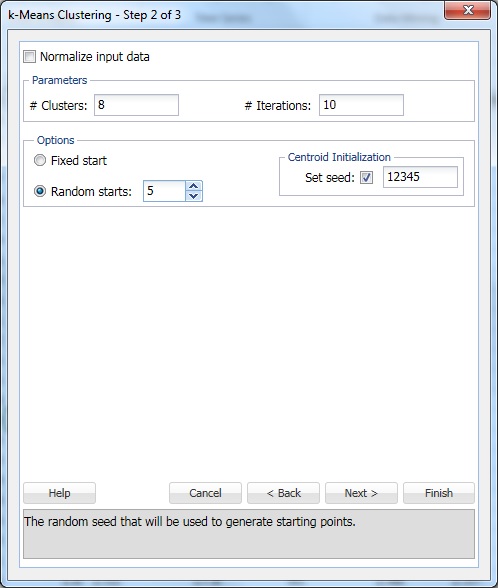
på # Klynger, skriv inn 8. Dette er parameteren k i k-means clustering algoritmen. Antall klynger skal være minst 1 og maksimalt antall observasjoner -1 i dataområdet. Sett k til flere forskjellige verdier og evaluer utgangen fra hver.
La #Iterasjoner ved standardinnstillingen 10. Verdien for dette alternativet bestemmer hvor mange ganger programmet vil starte med en innledende partisjon og fullføre klyngealgoritmen. Konfigurasjonen av klynger (og dataseparasjon) kan variere fra en startpartisjon til en annen. Programmet vil gå gjennom det angitte antall iterasjoner, og velg klyngekonfigurasjonen som minimerer avstandsmålet.
Sett Tilfeldig begynner til 5. Når dette alternativet er valgt, begynner algoritmen å bygge modellen fra et tilfeldig punkt. XLMiner genererer fem klyngesett og genererer produksjonen basert på den beste klyngen.
Set seed er valgt som standard. Dette alternativet initialiserer random number generator som brukes til å beregne de første klyngen sentroider. Innstilling av tilfeldig tallfrøet til en ikke-null verdi (standard 12345) sikrer at samme sekvens av tilfeldige tall brukes hver gang de første klyngens sentroider beregnes. Når frøet er null, initialiseres random number generator fra systemklokken, slik at sekvensen av tilfeldige tall er forskjellig hver gang sentroidene initialiseres. Sett frøet for å se suksessive løp av clustering-metoden som sammenlignbar.
Velg Alternativet Normaliser inndata for å normalisere dataene. I dette eksemplet vil dataene ikke bli normalisert. Velg Neste for å åpne Dialogboksen Trinn 3 av 3.
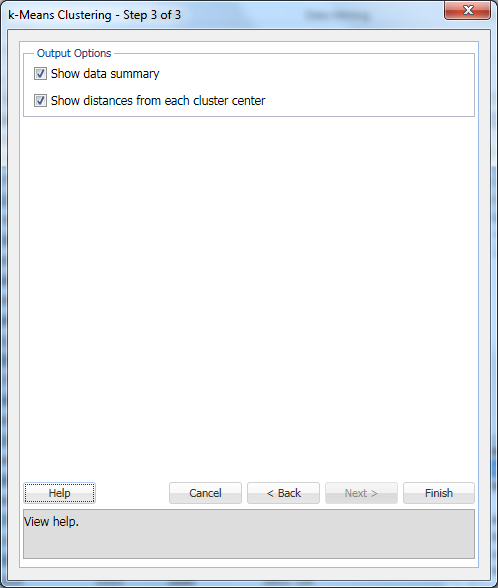
Velg Vis datasammendrag (standard) Og Vis avstander fra hvert klyngesenter (standard), og klikk Deretter På Fullfør.
k-Betyr Clustering metoden starter med k innledende klynger som angitt. Ved hver iterasjon tilordnes postene til klyngen med nærmeste sentroid eller senter. Etter hver iterasjon beregnes avstanden fra hver post til midten av klyngen. Disse to trinnene gjentas (postoppdraget og avstandsberegningen) til omfordeling av en post resulterer i en økt avstandsverdi.
når en tilfeldig start er angitt, genererer algoritmen k-klyngesentrene tilfeldig, og passer til datapunktene i disse klyngene. Denne prosessen gjentas for alle angitte tilfeldige starter. Utgangen er basert på klyngene som viser den beste passformen.
regnearket KM_Output1 settes inn umiddelbart til høyre for dataarket. I den øverste delen av utdata-regnearket vises de valgte alternativene.
I den midterste delen Av output-regnearket har XLMiner beregnet summen av de kvadrerte avstandene og bestemt starten med den laveste Summen Av Kvadratisk Avstand som Den Beste Starten (#5). Etter At Den Beste Starten er bestemt, genererer XLMiner gjenværende utgang med Den Beste Starten som utgangspunkt.
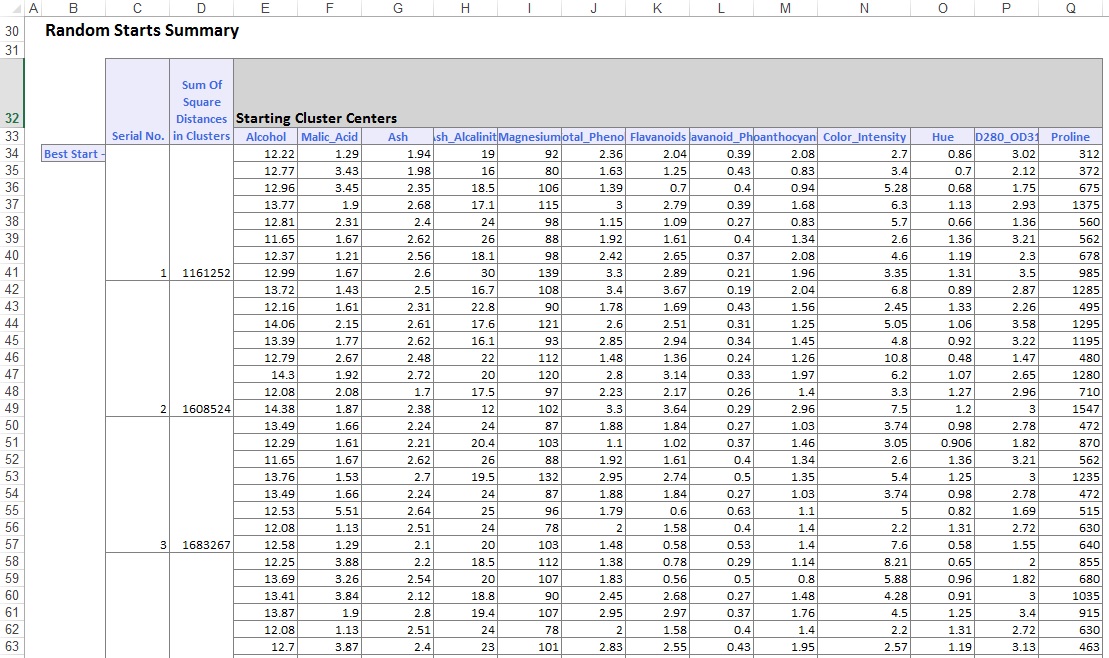
I den nederste delen Av utdatarearket har XLMiner oppført Klyngesentrene (vist nedenfor). Den øvre boksen viser variabelverdiene I Klyngesentrene. Cluster 8 har den høyeste gjennomsnittlige Alkohol, Total_fenoler, Flavanoider, Proanthocyaniner, Color_Intensity, Hue og Prolininnhold. Sammenlign denne klyngen Med Klynge 2, som har høyest Gjennomsnittlig Ash_Alcalinity og Nonflavanoid_Phenols.
den nedre boksen viser avstanden mellom Klyngesentrene. Fra verdiene i denne tabellen er Det fastslått At Klynge 3 er svært forskjellig Fra Klynge 8 på grunn av den høye avstandsverdien på 1,176.59, Og Klynge 7 er nær Klynge 3 med en lav avstandsverdi på 89,73.
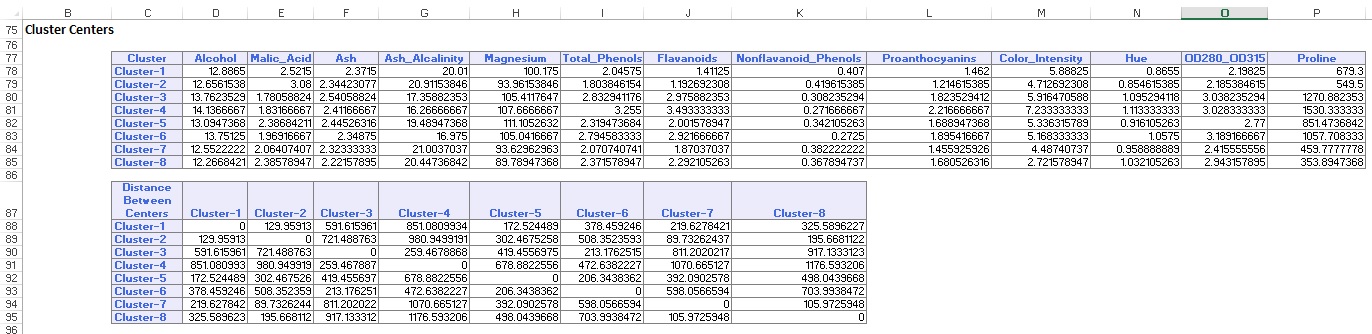
Datasammendraget (nedenfor) viser antall poster (observasjoner) inkludert i hver klynge og gjennomsnittlig avstand fra klyngemedlemmer til midten av hver klynge. Cluster 6 har den høyeste gjennomsnittlige avstanden på 42,79, og inkluderer 24 poster. Sammenlign denne klyngen Med Klynge 2, som har den minste gjennomsnittlige avstanden på 29,66, og inkluderer 26 medlemmer.
Klikk på km_clusters1-regnearket. Dette regnearket viser klyngen som hver post er tilordnet, og avstanden til hver av klyngene. For Den første posten er avstanden Til Klynge 6 minimumsavstanden på 23.205, så denne første posten er tildelt Klynge 6.